Pytorch is a deep learning framework and a scientific computing package
The scientific computing aspect of PyTorch’s is primarily a result PyTorch’s tensor library and associated tensor operations. That means you can take advantage of Pytorch for many computing tasks, thanks to its supporting tensor operation, without touching deep learning modules.
Important to note that PyTorch tensors and their associated operations are very similar to numpy n-dimensional arrays. A tensor is actually an n-dimensional array.
Pytorch builds its library around Object Oriented Programming(OOP) concept. With object-oriented programming, we orient our program design and structure around objects. The tensor in Pytorch is presented by the object torch. Tensor which is created from numpy ndarray objects. Two objects share memory. This makes the transition between PyTorch and NumPy very cheap from a performance perspective.
With PyTorch tensors, GPU support is built-in. It’s very easy with PyTorch to move tensors to and from a GPU if we have one installed on our system. Tensors are super important for deep learning and neural networks because they are the data structure that we ultimately use for building and training our neural networks.
Talking a bit about history.
The initial release of PyTorch was in October of 2016, and before PyTorch was created, there was and still is, another framework called Torch which is also a machine learning framework but is based on the Lua programming language. The connection between PyTorch and this Lua version, called Torch, exists because many of the developers who maintain the Lua version are the individuals who created PyTorch. And they have been working for Facebook since then till now.
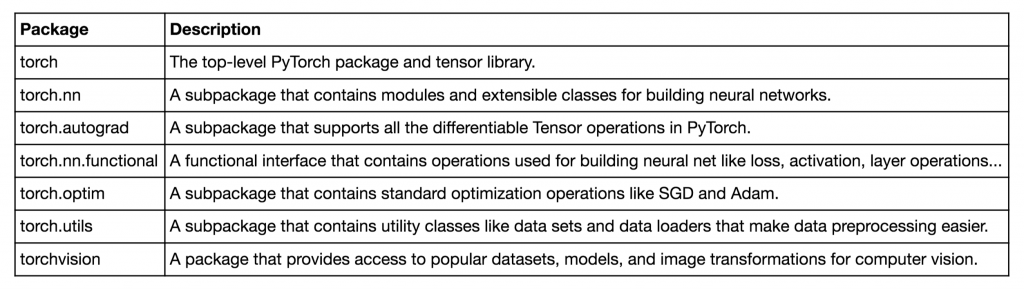
Below are the primary PyTorch modules we’ll be learning about and using as we build neural networks along the way.
Why use Pytorch for deep learning?
- PyTorch’s design is modern, Pythonic. When we build neural networks with PyTorch, we are super close to programming neural networks from scratch. When we write PyTorch code, we are just writing and extending standard Python classes, and when we debug PyTorch code, we are using the standard Python debugger. It’s written mostly in Python and only drops into C++ and CUDA code for operations that are performance bottlenecks.
- It is a thin framework, which makes it more likely that PyTorch will be capable of adapting to the rapidly evolving deep learning environment as things change quickly over time.
- Stays out of the way and this makes it so that we can focus on neural networks and less on the actual framework.
Why PyTorch is great for deep learning research
The reason for this research suitability is that Pytorch uses a dynamic computational graph, in contrast with tensorfow which uses a static computational graph, to calculate derivatives.
Computational graphs are used to graph the function operations that occur on tensors inside neural networks. These graphs are then used to compute the derivatives needed to optimize the neural network. Dynamic computational graph means that the graph is generated on the fly as the operations are created. Static graphs that are fully determined before the actual operations occur.