Motivation
What makes computers useful for us is primarily the ability to solve problems. The procedure in which computers solve a problem is an algorithm. In the recent context of an increasing number of algorithms available for solving data-related problems, there is increasing demand for a higher level of understanding of algorithm’s performance for data scientists to choose the right algorithms for their problems.
Having a general perception of the efficiency of an algorithm would help to shape the thought process for creating or choosing better algorithms. With this intention in mind, I would like to create a series of posts to discuss what makes a good algorithm in practice, or for short, efficient algorithm. And this article is the first step of the journey.
Define Efficiency
An algorithm is considered efficient if its resource consumption, also known as computational cost, is at or below some acceptable level. Roughly speaking, ‘acceptable’ means: it will run in a reasonable amount of time or space on an available computer, typically as a function of the size of the input.
There are many ways in which the resources used by an algorithm can be measured: the two most common measures are speed and memory usage. In the next 2 sections, we will be looking at the two different perspectives for measuring the efficiency of an algorithm from theoreticians and practitioners.
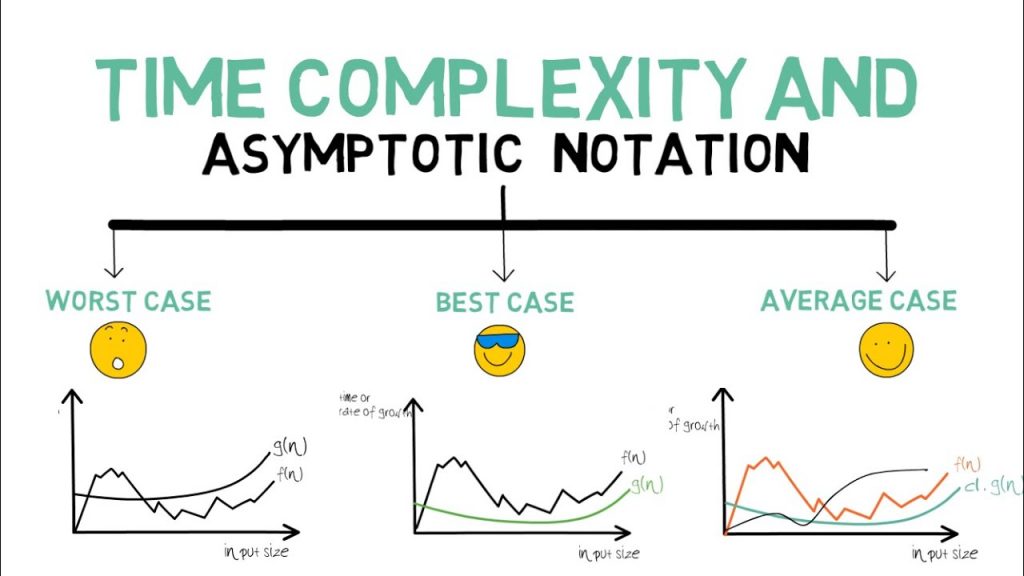
Theoreticians perspective
Practitioner perspective
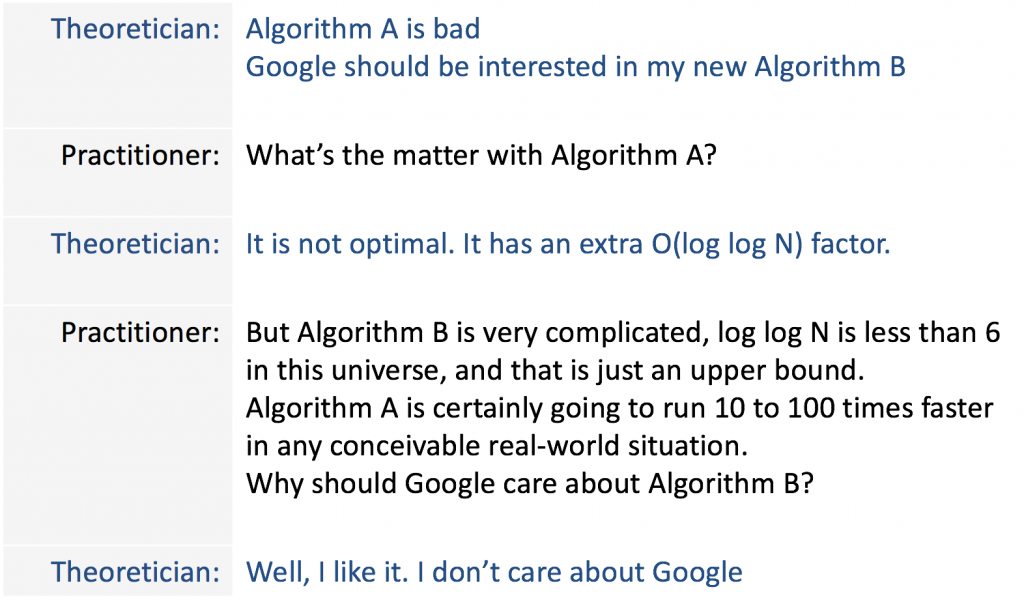
In practice, other factors that can affect the efficiency of an algorithm, such as requirements for accuracy and/or reliability. As detailed below, how an algorithm is implemented can also have a significant effect on actual efficiency, though many aspects of this relate to optimization issues.
Implementation issues can also effect efficiencies, such as the choice of programming language, or how the algorithm is coded, or the choice of a compiler for a particular language, or the compilation options used, or even the operating system being used. In many cases, a language implemented by an interpreter may be much slower than a language implemented by a compiler.