Contents
Overview
(AWS – Batch Process and Data Analytics)
Today, I will describe our current system references architecture for Batch processing and Data Analytics for the sales report system. Our mission is to create a big data analytics system that interacts with Machine Learning features for insights and prediction. Nowadays, too many AI companies are researching and were applied machine learning features to their system to improve services. We also working to research and applied machine learning features to our system such as NLP, Forecast, OCR … that help us have the opportunity to provide better service for customers.
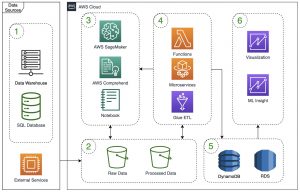
- Data Source
We have various sources from multiple systems including both on-premise and on-cloud with a large dataset and unpredictable frequent updates. - Data lake storage
We use S3 as our data lake storage with unlimited types and volumes. That helps us easy to scale our system easily - Machine Learning
We focus on Machine learning to build great AI solutions from our dataset. Machine learning models will predict for insight and integration directly to our system as microservices. - Compute
Compute machines are most important in our system. We choose fit machine services as infrastructure or serverless to maximize optimize cost and performance.
– We using AWS lambda functions for small jobs such as call AI services, small dataset processing, and integrating
– We using AWS Glue ETL to build ETL pipeline and build custom pipelines with AWS step functions.
– We also provide web and APIs service for end-users that system building by microservices architecture and using AWS Fargate for hosting services - Report datastore
After processing data and export insight data from predictions we store data in DynamoDB and RDS for visualization and build-in AWS insight features. - Data analytics with visualization and insights
We are using AWS Quicksight and insight for data analytics
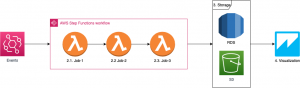
Data Processing Pipeline: AWS Event + AWS Step Function + AWS Lambda
According to the specific dashboard, we have specific data processing pipeline to process and prepare data for visualization and insights. Here is our standard pipeline with AWS Step functions orchestrators. We want to hold everything basic as possible. We using AWS Events for schedule, and Lambda functions as interacting functions.
– Advantages: Serverless and easy to develop and scale
– Disadvantages: Most depend on AWS services and challenges when exceeding the limitation of AWS services such as Lambda functions processing time.
– Most use case scenario: Batch data processing pipeline.
What are the strong points in our system?
- Using serverless compute for data processing and microservices architecture
- Easy to develop, deploy and scale system without modifying
- Flexibility to using build-in services and build custom Machine Learning model with AWS SageMaker
- Separately with Datasource systems in running
- Effectively data lake processing
Conclusion
This architecture is basic and I hope you can get something in here. We focus to describe our current system and it is building to larger than our design with more features in the future; we should choose a flexible solution for easy to maintain and replaceable. When you choose any architecture or service which helps you resolve your problems, you should consider what is the best fit service for your current situation, and no architecture/service can resolve all problems that depend on the specific problem. And avoid the case for solution finding for problems 😀
— — — — — — — — — — — — — — — —