Contents
Overview for Build a Data lake with AWS(Beginner)
AWS Lake Formation enables you to set up a secure data lake. A data lake is a centralized, curated, and secured repository storing all your structured and unstructured data, at any scale. You can store your data as-is, without having first to structure it. And you can run different types of analytics to better guide decision-making—from dashboards and visualizations to big data processing, real-time analytics, and machine learning.
The challenges of data lakes
The main challenge to data lake administration stems from the storage of raw data without content oversight. To make the data in your lake usable, you need defined mechanisms for cataloging and securing that data.
Lake Formation provides the mechanisms to implement governance, semantic consistency, and access controls over your data lake. Lake Formation makes your data more usable for analytics and machine learning, providing better value to your business.
Lake Formation allows you to control data lake access and audit those who access data. The AWS Glue Data Catalog integrates data access policies, making sure of compliance regardless of the data’s origin.
Set up the S3 bucket and put the dataset.
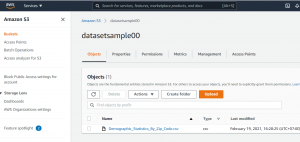
Set up Data Lake with AWS Lake Formation.
Step 1: Create a data lake administrator
First, designate yourself a data lake administrator to allow access to any Lake Formation resource.
Step 2: Register an Amazon S3 path
Next, register an Amazon S3 path to contain your data in the data lake.
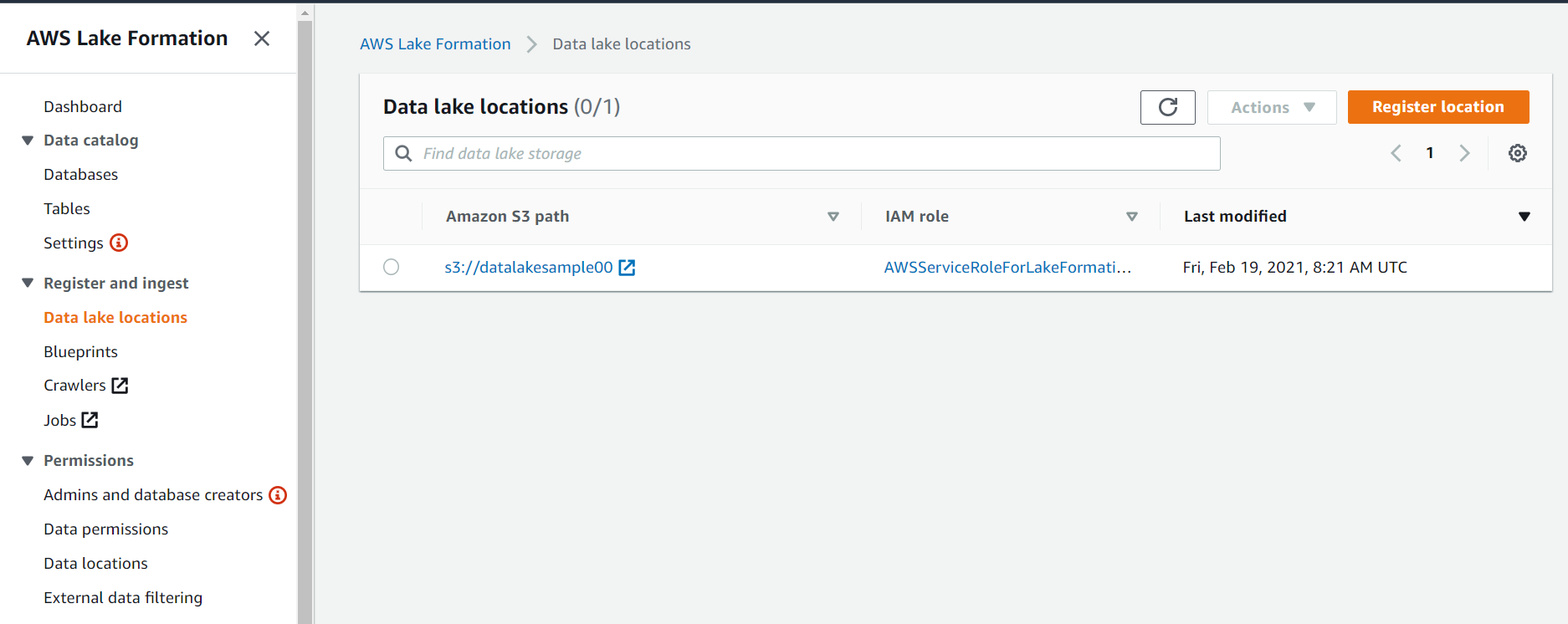
Step 3: Create a database
Next, create a database in the AWS Glue Data Catalog to contain the datasetsample00 table definitions.
- For Database, enter datasetsample00-db
- For Location, enter your S3 bucket/ datasetsample00.
- For New tables in this database, do not select Grant All to Everyone.
Step 4: Grant permissions
Next, grant permissions for AWS Glue to use the datasetsample00-db database. For the IAM role, select your user and AWSGlueServiceRoleDefault.
Grant your user and AWSServiceRoleForLakeFormationDataAccess permissions to use your data lake using a data location:
- For the IAM role, choose your user and AWSServiceRoleForLakeFormationDataAccess.
- For Storage locations, enter s3:// datalake-hiennu-ap-northeast-1.
Step 5: Crawl the data with AWS Glue to create the metadata and table
In this step, a crawler connects to a data store, progresses through a prioritized list of classifiers to determine the schema for your data, and then creates metadata tables in your AWS Glue Data Catalog.
Create a table using an AWS Glue crawler. Use the following configuration settings:
- Crawler name: samplecrawler.
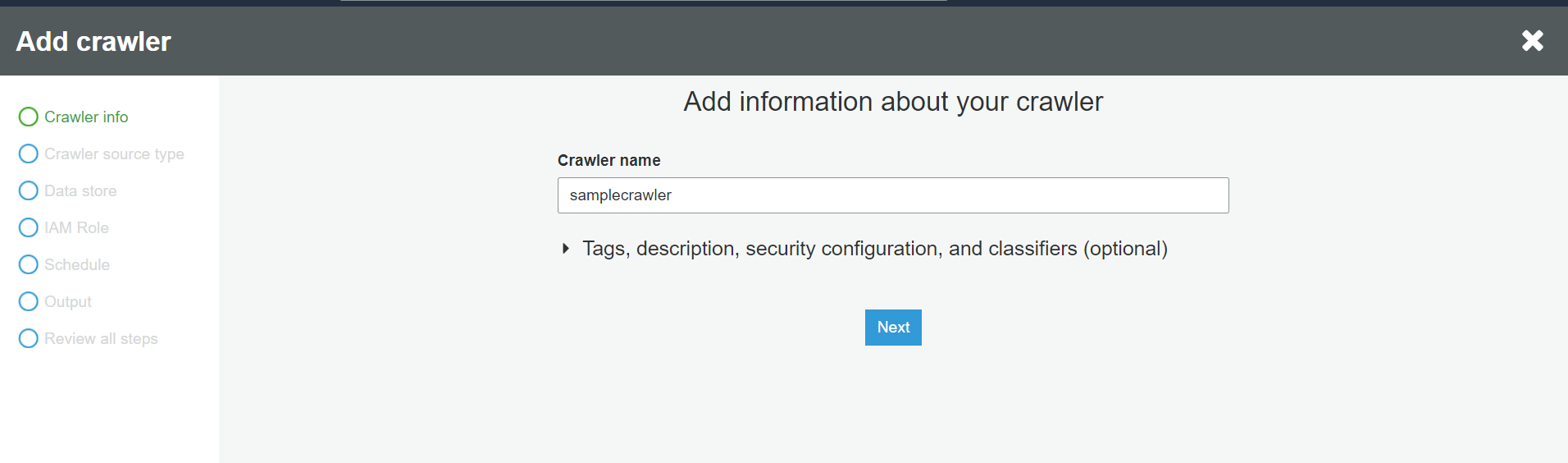
- Datastores: Select this field.
- Choose a data store: Select S3.
- Specified path: Select this field.
- Include path: s3://datalake-hiennu-ap-northeast-1/datasetsample00.
- Add another datastore: Choose No.
- Choose an existing IAM role: Select this field.
- IAM role: Select AWSGlueServiceRoleDefault.
- Run on-demand: Select this field.
- Database: Select datasetsample00-db.
Step 6: Grant access to the table data
Set up your AWS Glue Data Catalog permissions to allow others to manage the data. Use the Lake Formation console to grant and revoke access to tables in the database.
- In the navigation pane, choose Tables.
- Choose Grant.
- Provide the following information:
- For the IAM role, select your user and AWSGlueServiceRoleDefault.
- For Table permissions, choose Select all.
Step 7: Query the data with Athena
Query the data in the data lake using Athena.
- In the Athena console, choose Query Editor and select the datasetsample00-db
- Choose Tables and select the datasetsample00 table.
- Choose Table Options (three vertical dots to the right of the table name).
- Select Preview table.
Athena issues the following query: SELECT * FROM datasetsample00 limit 10;