Contents
In NLP, encoding text is the heart of understanding language. There are many implementations like Glove, Word2vec, fastText which are aware of word embedding. However, these embeddings are only useful for word-level and may not perform well in case we would like to expand to encode for sentences or in general, greater than one word. In this post, we would like to introduce one of the SOTAs for such a task: the Universal Sentence Encoder model
1. What is USE (UNIVERSAL SENTENCE ENCODER MODEL)?
The Universal Sentence Encoder (USE) encodes text into high dimensional vectors (embedding vectors or just embeddings). These vectors are supposed to capture the textual semantic. But why do we even need them?
A vector is an array of numbers of a particular dimension. With the vectors in hand, it’s much easier for computers to work on textual data. For example, we can say two data points are similar or not just by calculating the distance between the two points’ embedding vectors.

(Image source: https://amitness.com/2020/06/universal-sentence-encoder/)
The embedding vectors then in turn can be used for other NLP downstream tasks such as text classification, semantic similarity, clustering…
2.USE architecture
It comes with two variations with the main difference resides in the embedding part. One is equipped with the encoder part from the famous Transformer architecture, the other one uses Deep Averaging Network (DAN)
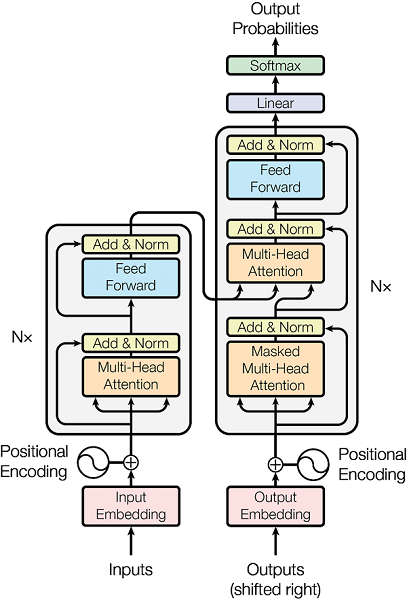
2.1 Transformer encoder
The Transformer architecture is designed to handle sequential data, but not in order like the RNN-based architectures. It uses the attention mechanism to compute context-aware representations of words in a sentence taking into account both the ordering and significance of all the other words. The encoder takes input as a lowercased PTB tokenized string and outputs the representations of each sentence as a fixed-length encoding vector by computing the element-wise sum of the representations at each word position. Due to this feature, the Transformer allows for much more parallelization than RNNs and therefore reduced training times.
Universal Sentence Encoder uses only the encoder branch of Transformer to take advantage of its strong embedding capacity.
2.2 Deep Averaging Network (DAN):
DAN is a simple Neural Network that takes an average of embeddings for words and bi-grams and then passed the “combined” vector through a feedforward deep neural network (DNN) to produce sentence embeddings. Similar to the Transformer encoder, DAN takes as input a lowercased PTB tokenized string and outputs a 512-dimensional sentence embedding.
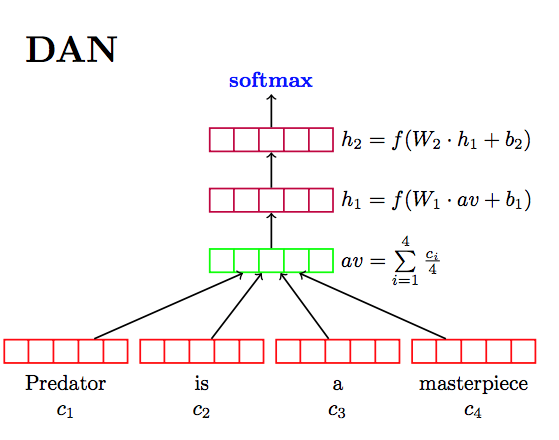
The two have a trade-off of accuracy and computational resource requirement. While the one with the Transformer encoder has higher accuracy, it is computationally more intensive. The one with DNA encoding is computationally less expensive and with little lower accuracy.
3. How was it trained?
The key idea for training this model is to make the model work for generic tasks such as:
- Modified Skip-thought
- Conversational input-response prediction
- Natural language inference.
3.1 Modified skip-thought:
given a sentence, the model needs to predict the sentences around it.