Contents

-
3.2 Conversational input-response prediction:
In this task, the model needs to predict the correct response for a given input among a list of correct responses and other randomly sampled responses.
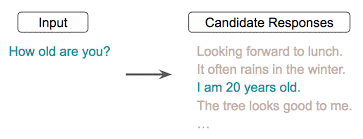
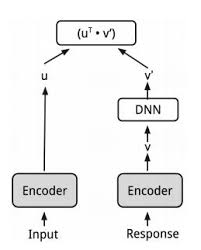
(Image source: https://arxiv.org/pdf/1804.07754.pdf)
-
3.3 Natural language inference (NLI):
is the task of determining whether a “hypothesis” is true (entailment), false (contradiction), or undetermined (neutral) given a “premise”.
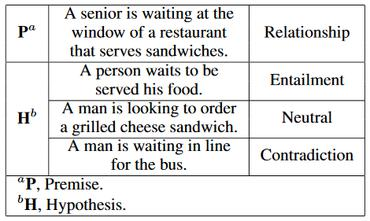
The intuition is that by doing such training, the model can capture the most informative features and discard noise from the text. This output embedding, in turn, will be applied to a wide variety of NLP tasks such as relatedness, clustering, paraphrase detection, and text classification.
-
4. Results of UNIVERSAL SENTENCE ENCODER MODEL
To compare the performance between using transfer learning via pre-trained word embedding and no using any transfer learning, Word Embedding Association Test (WEAT) was used. WEAT includes:
The results are summarized on the table as follows:
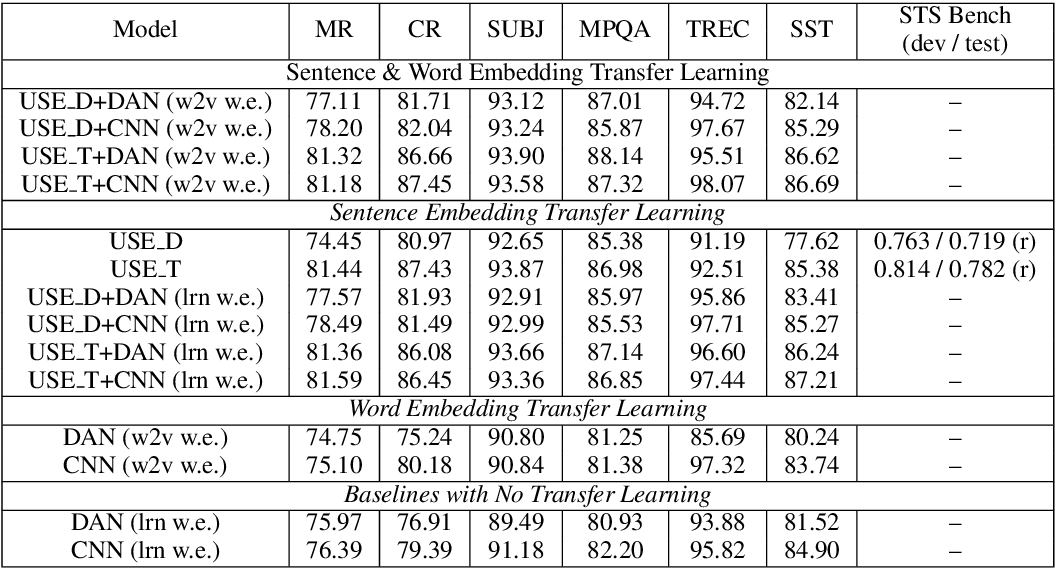
The results show that:
- Transfer learning from the Transformer based sentence encoder usually performs as good or better than transfer learning from the DAN encoder
- Models that make use of sentence-level transfer learning tend to perform better than models that only use word-level transfer.
- The best performance on most tasks is obtained by models that make use of both sentence and word level transfer
References:
Glove
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation, https://nlp.stanford.edu/pubs/glove.pdf
Word2vec
Mikolov, Tomas, et al. Efficient Estimation of Word Representations in Vector Space. Jan. 2013. arxiv.org, https://arxiv.org/abs/1301.3781v3.
fasText
Bojanowski, Piotr, et al. Enriching Word Vectors with Subword Information. July 2016. arxiv.org, https://arxiv.org/abs/1607.04606v2.
Transformer
Vaswani, Ashish, et al. Attention Is All You Need. June 2017. arxiv.org, https://arxiv.org/abs/1706.03762v5.
DAN
Iyyer, Mohit, et al. “Deep Unordered Composition Rivals Syntactic Methods for Text Classification.” Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Association for Computational Linguistics, 2015, pp. 1681–91. ACLWeb, doi:10.3115/v1/P15-1162
Hiring Data Scientist / Engineer
We are looking for Data Scientist and Engineer.
Please check our Career Page.
AI / Data Science Project
Please check about experiences for Data Science Project
Vietnam AI / Data Science Lab

Please also visit Vietnam AI Lab