When exploring the data set, we can see that some ingredients such as “onion”, “oil” may be expressed as “Onion”, ‘Oil”. They are the same ingredient, but one without a cap lock and one with a cap lock. Sometimes we will have ingredients as “onion” and “onions”. Sometimes the same ingredients will be “the” (stop word) in front, while others are not. All of these can be fixed using some simple NLP techniques. Fixing up typos is also part of NLP, but it will require a bit of work. Pre-processing data using NLP is an important step to build the classification model since the list of features are words, not numbers.
Now, let us look a bit closer at the distribution of ingredients in a few cuisines. Here are some of the example:
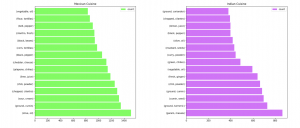
We can see that there are some unique ingredients in each cuisine such as “tortillas” in Mexican cuisine. However, there are a lot of overlapping ingredients as well such as “olive oil”.
Let make a hypothesis that cuisines from different Continents may not share a lot of similar ingredients.
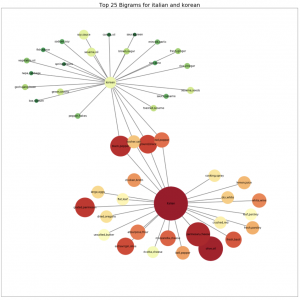
The figure above compares the ingredients of “Italian” and “Korean”. We can observe that the overlapping ingredients are mostly generic ingredients such as salt and peppers. If we remove these ingredients, we would expect that the model should have no problems classify these two cuisines.
On the other hand, let us look at cuisines from the same Continents.
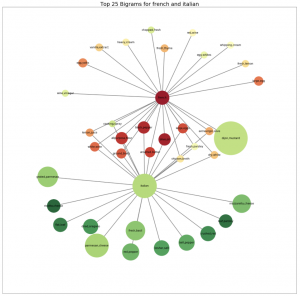
Here, we can see that similar cultures share a lot of ingredients. We can expect that from a random list of ingredients, deciding which cuisine it belongs to will be much harder.
Hopefully, so far you can see that exploring data sets is an important step. It will give you an overview of the data and help you make a better decision on how to pre-process it or which model may work best for this kind of problem.
2. Imbalance Data
Let assume for now that we have a small training data set.
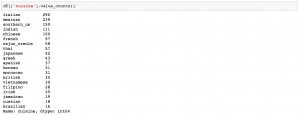
From the figure above, we can see that we have about 290 recipes from ‘Italian’ cuisine and only 16 recipes from ‘Brazilian’ cuisine.
If we let the training data set as it is and build our classification model, one problem we may run into is prediction bias. That is, the model only exposes to recipes mainly from ‘Italian’, ‘Mexican’, etc, so when it is asked to predict a cuisine from a new recipe, it will more likely predict the cuisine comes from a larger representative group from the training data.
Imbalance data is an important issue that needs to be tackled before training the model. There are a few common methods to resolve imbalance data such as “up-sampling”, “down-sampling”, sometimes a mixture of the 2 are used.
‘Down-sampling’ can be achieved by randomly choosing recipes from all the bigger cuisine groups such as ‘Italian’ to match the sample size of the smallest group ‘Brazilian’. That is, we will randomly choose a recipe from all cuisine except ‘Brazilian’ so that their sample recipe for the training set will be the same size as the recipe from ‘Brazilian’ (16 recipes). Down-sampling is not a practical step when the training sample is small. If we down sampling every cuisine to 16 recipes, the total training set will be very small and the classification model may result in poor accuracy.