Contents
How about ‘up-sampling’, where we make every cuisine in the list be the same size as the one with the biggest recipe. This can be done by adding recipes to each smaller size cuisine by random sampling. However, for this exercise, we see that upsizing a sample of 16 recipes to a sample of 290 recipes will result in a lot of duplication of recipes. This can lead to an issue of overfitting for cuisine such as ‘Brazilian’, ‘Russian’, etc.
The best way to handle this is to do a mixture of ‘up-sampling’ and ‘down-sampling’. That is, we can set a fixed sample size that we think could result in a large enough training data set as well as reduce the risk of overfitting and ‘up-sampling’ smaller set to this value as well as ‘down-sampling’ larger set to this value.
We constructed a Decision Tree with depth =2 on this small sample training set. We use a mixture of ‘up-sampling’ and ‘down-sampling’ to a recipe size of 100 for each cuisine to deal with Imbalance data. Here is the result of the classification on the evaluation set
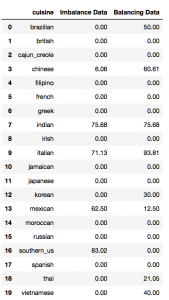
We can see that without balancing the recipe in the training data, small sample size cuisine such as ‘Brazilian’ has an accuracy of 0%. After performing ‘up-sampling’ and ‘down-sampling’, the model is able to give a better classification.
Hiring Data Scientist / Engineer
We are looking for Data Scientist and Engineer.
Please check our Career Page.
Data Science Blog
Please check our other Data Science Blog
Hiring Data Scientist / Engineer
We are looking for Data Scientist and Engineer.
Please check our Career Page.
AI / Data Science Project
Please check about experiences for Data Science Project
Vietnam AI / Data Science Lab
