Contents
In Data Science, before building a predictive model from a particular data set, it is important to explore and perform pre-processing data. In this blog, we will illustrate some typical steps in data pre-processing.
In this particular exercise, we will build a simple Decision Tree model to classify the food cuisine from the list of ingredients. The data for this exercise can be taken from:
https://www.kaggle.com/kaggle/recipe-ingredients-dataset
From this exercise, we will show the importance of data pre-processing. This blog will be presented as follow:
- Data Exploration and Pre-processing.
- Imbalance Data.
1. Data Exploration and Pre-processing
When you are given a set of data, it is important to explore and analyze them before constructing a predictive model. Let us first explore this data set.

From the first 10 items of this data set. We observe that given a particular cuisine, the list of ingredients may be different.
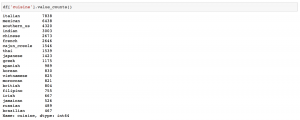
From this data set, we can find out that there are 20 different cuisines and the recipes distribution is not uniform. For example, recipes from ‘Italian’ cuisine take 19.7% of all the data set, while there is only 1.17% of the recipes are coming from ‘Brazilian’ cuisine.
Now, let us explore further into this data set. Let us look at the top 15 ingredients
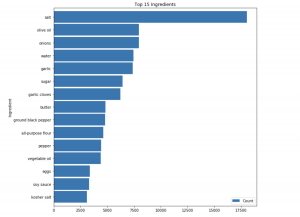
If we look at the top 15 ingredients, we will see that they include “salt”, “water”, “sugar”, etc. They are all generic and can be found in every cuisine. Intuitionally, if we remove these ingredients from the classification model, the accuracy of the classification should not be affected.
In the classification model, we would refer that recipes in each cuisine to have unique ingredients to that country. This will help the model to easily identify which cuisine this recipe comes from.
After removing all the generic ingredients (salt, water, sugar, etc) from the data set, we look at the top 15 ingredients again.
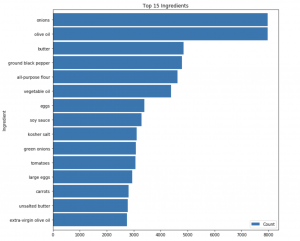
It looks like we can remove more ingredients, but a decision which one to remove properly leave to someone with a bit more domain of knowledge in cooking. For example, some country may use ‘onion’ in their recipe, the other may use ‘red onion’. So it is better not to overly filter out too many generic ingredients.
Now, we look at the distribution of ingredients in each recipe in the data set.
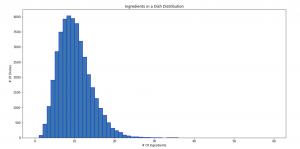
Some recipes have only 1 to 2 ingredients in the recipe, some may have up to 60. It is probably best to remove those recipes with so few ingredients out of the data set, as the number of ingredients may not be representative enough for the classification model. What is the minimum number of ingredients require to classify the cuisine? The short answer is no one knows. It is best to experiment it out by removing data sets with 1, 2, 3, etc ingredients and re-train the model and compare the accuracy to decide which one works best for your model.
The ingredients in the recipe are all words, to do some further pre-processing, we will need to use some NLP (Natural Language Processing).