Contents
This involves two separate steps:
1) Automatic: for each word in the summary, if it does not appear in the full text, compare its embedding vector to all other words’ embeddings in a pairwise fashion based on their cosine distance. Retain the *closest pairing for each summary word.
2) These pairs are then passed on for human evaluation by a native speaker as outlined in the figure below:
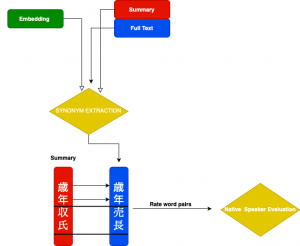
For 2), the human annotator(s) are instructed to assign ratings as follows:
If the automatically matched word in the pair:
- Is not a synonym, assign: 0
- Has some relationship, assign: 1
- Has a strong, but not a perfect relationship, assign: 2
- Is a good synonym for original word, assign: 3
The table below shows an excerpt of the human ratings’ results. The first column lists the original word in the summary for which we are searching synonyms in the text. The “Skipgram” and “CBOW” columns list the best candidate for that embedding with the respective rating to their right. The last column records if there was a better synonym in the full text that has not been matched by the model(s).
| Original Sum Word | Skipgram | Skipgram Rating | CBOW | CBOW Rating | *Best Synonym |
| HD
(Holdings) |
ホールディング
(Holding) |
2 | ホールディング
(Holding) |
2 | ホールディングス
(Holdings) |
| 益
(Profit) |
利益
(Profit) |
3 | 利益
(Profit) |
3 | |
| 宿
(Inn) |
旅
(Tourist) |
1 | ホテル
(Hotel) |
2 | 旅館
(Ryokan) |
The results show that both models can extract meaningful relationships based on vector embeddings.
Specifically, “HD”, a common abbreviation for “holdings” is mapped to “ホールディング” (Holding), the katakana equivalent. The shorter summary word “益” is correctly mapped to “利益”, both meaning “profit”. For the summary word “宿” (Inn), the best candidate “旅館” was not found by either model, but both were able to discover related alternatives: “旅” (Tourist) and “ホテル” (Hotel).
In the above post, we have presented a naïve approach to estimate the usefulness of (sub)word embeddings that does not involve having to design an explicit proxy task or utilizing an external data set. There is a human evaluation step to rate the similarity between extracted pairs. This evaluation is, however, tailored more specifically to the data at hand and therefore going to be more useful.
REFERENCES
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Sakaizawa, Y., & Komachi, M. (2018, May). Construction of a Japanese Word Similarity Dataset. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
Faruqui, Manaal, et al. Problems With Evaluation of Word Embeddings Using Word Similarity Tasks. Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP.2016.
Kudo, T., & Richardson, J. (2018, November). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 66-71).
Kudo, Taku. Mecab: Yet another part-of-speech and morphological analyzer. http://mecab. sourceforge. jp (2006).
Athiwaratkun, B., Wilson, A., & Anandkumar, A. (2018, July). Probabilistic FastText for Multi-Sense Word Embeddings. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1-11).
Data Science Blog
Please check our other Data Science Blog
Hiring Data Scientist / Engineer
We are looking for Data Scientist and Engineer.
Please check our Career Page.
AI / Data Science Project
Please check about experiences for Data Science Project
Vietnam AI / Data Science Lab
