Contents
Do even the best DNN models understand language?
New advances, new excitement
Without any doubt, Deep Neural Networks (DNNs) have brought huge improvements to the NLP world recently. News like an AI model using DNN can write articles like a human or can write code to create a website like a real developer comes to mainstream media frequently. A lot of these achievements would have been surreal if we talked about them just a few years ago.
One of the most influential models is Bert (Bidirectional Encoder Representations from Transformers), created by Google in 2018. Google claimed with Bert, they now can understand searches better than ever before. Not stopped there, they even took it further by saying embedding this model to its core search engine(SE) “representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search”. Impressed by the bold claim, I took my liberty to check how the SE works with a COVID-related inquiry like the one below.
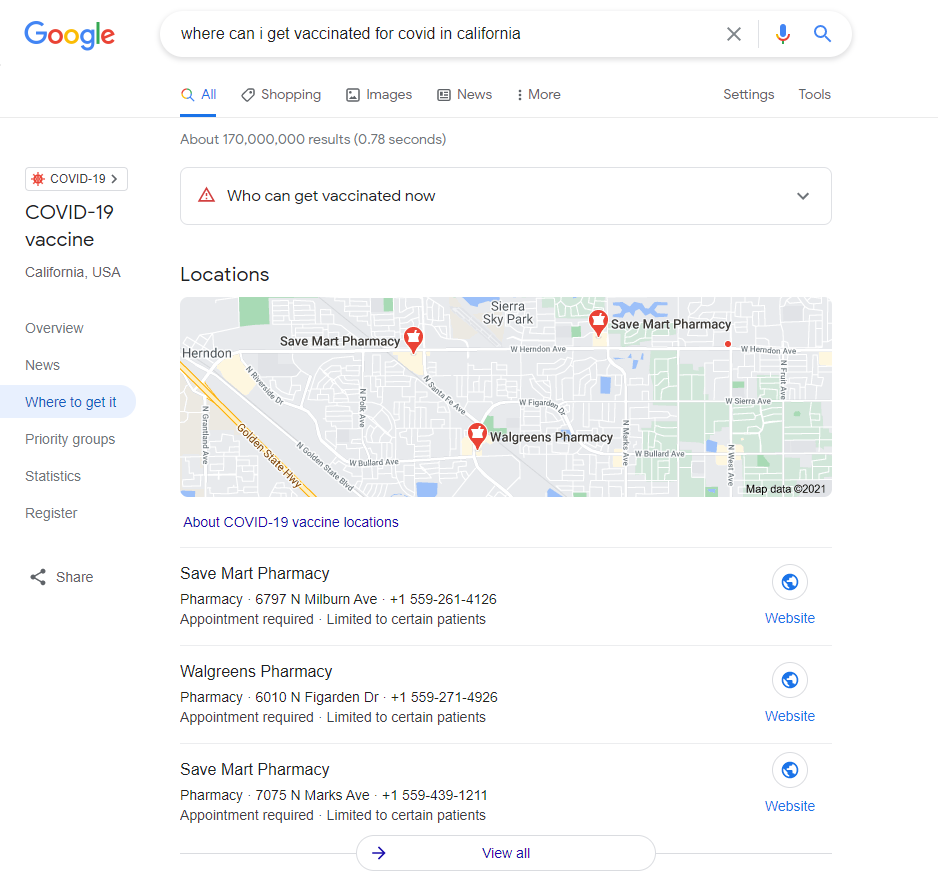
Figure 1: The Search Engine doesn’t just give out locations where vaccine shots are provided but also suggests who is eligible for getting the shots. This result cannot come from a keyword-based search mechanism. And Yes, so far, the result seems to justify their confident claim.
However, Bert was not the only champion in the game. Another powerful language model which was released more recently has come with its advantages. It was GPT-3. Open AI built the model with 175 billion parameters which were 100 times more parameters than its predecessor GPT-2. Due to this large number of parameters and the extensive dataset it has been trained on, GPT-3 performed impressively on the downstream NLP tasks without fine-tuning. Here is an article from MTI Review written by this gigantic model.

Figure 2: The italicized part was input they fed the model, served as a prompt. This article talks about a unicorn with such fluent English and a high level of confidence, almost indistinguishable from human writing. I would have been convinced the piece of writing was genuine if I did not know the creature did not exist.
Many people were astounded at the text that was produced, and indeed, this speaks to the remarkable effectiveness of the particular computational systems. It seems, for some not-crystal-clear reasons, the models understand language. If that’s true, it would be the first step for AI to think like humans. Unsurprisingly, the media took the news by storm. People started to talk about the societal impacts like workforce replace by AI systems. Some even went further by saying humans might be in danger 😉 But really, are we there yet?
Do the models understand language?
So, are the models that great? Are these models capable of understanding language or are they somewhat gaming the whole system? A series of recent papers claimed that models like BERT don’t understand the language in any meaningful way. One of the reasons for their outstanding results might come from their training and testing datasets.
In the paper: “Probing Neural Network Comprehension of Natural Language Arguments”, the authors believe exploiting linguistic cues plays a major part in the models’ performance. The authors altered the evaluation datasets in a way that would make no difference to how the results were interpreted. They started with removing negations such as “not”, “cannot” but kept the meaning of the sentences. For example: “it is not raining, therefore, I can go for a run”, was changed to “it is raining, therefore, I cannot go for a run”. As a result, the SOTA models struggled badly, almost as bad as a random system.
In another paper called “Right for the Wrong Reasons”, the authors hypothesized three syntactic heuristics these models might use to score high in the NLI task[8]. For details of the heuristics, please refer to the image below.

Figure 3: The authors proved that the syntactic overlaps between premise and hypothesis affect the NLP models’ predictive capability significantly. Thomas McCoy and Ellie Pavlick, 2020.
The points were being made pretty clear here. The Bert-like models seem to use statistical “cues” as a crude heuristic to get better results, far away from true “reasoning” or “inference” skills needed to understand human language.
And not just because of the flaws in the datasets, we need to concern about the way we train the models as well. Up to now, we tend to associate models with more parameters, trained with more text data in an “optimal” way with better “understanding” language capability. In the paper “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”, Emily Bender and Alexander Koller investigated whether LMs such as GPT-3 or BERT can ever learn to “understand” language, no matter how much data we feed them.
They started with defining form and meaning. According to their paper, form is the identifiable, physical part of a language. The marks and symbols that represented the language, such as the symbols on a page or the pixels and bytes on a webpage. The meaning is how these elements relate to things in the external world.
It turns out, up to now, we have not figured out how to feed the models the outside world knowledge effectively. It’s like someone tries to learn a new language by reading books without knowing the connection between the content of the books to the world. Like you learn the word “apple” without knowing an actual apple outside in the world. To a certain extent, these models lack the common sense of the world. Without such knowledge, from a theoretical point of view, it’s impossible for any DNN models to truly understand language.
Tentative conclusion
We may question the NLP models’ ability to understand language like a human being, but we cannot deny how significantly they have evolved in the past few years. If the datasets were not “hard” enough to train and properly evaluate the model, we can always construct more advanced ones. NA, SuperGLUE, or XTREME are few examples. If they lack common sense knowledge, a new type of architecture like a multi-modal one can be devised and improved to handle such a new type of input. Even if they are “cheating” to gain more performance, that shows how far they have come. For me, understanding their limits are just to make them better and the future of applying DNN models to NLP tasks remains very bright. 😉
Ps: This writing is by no means a comprehensive review on the topic 😊
References
- https://chrisgpotts.medium.com/is-it-possible-for-language-models-to-achieve-language-understanding-81df45082ee2
- https://neptune.ai/blog/ai-limits-can-deep-learning-models-like-bert-ever-understand-language
- https://medium.com/swlh/gpt-3-understands-nothing-1d6f6a13cab2#:~:text=GPT%2D3%20(Generative%20Pre%2D,it%20then%20aims%20to%20complete.
- https://dzone.com/articles/gpt-3-does-not-understand-what-it-is-saying
- https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3
- https://neptune.ai/blog/ai-limits-can-deep-learning-models-like-bert-ever-understand-language
- https://plato.stanford.edu/entries/chinese-room/
- https://en.wikipedia.org/wiki/Natural-language_understanding
Data Science Blog
Please check our other Data Science Blog
Hiring Data Scientist / Engineer
We are looking for Data Scientist and Engineer.
Please check our Career Page.
AI / Data Science Project
Please check about experiences for Data Science Project
Vietnam AI / Data Science Lab
