Contents
For main_category variable:
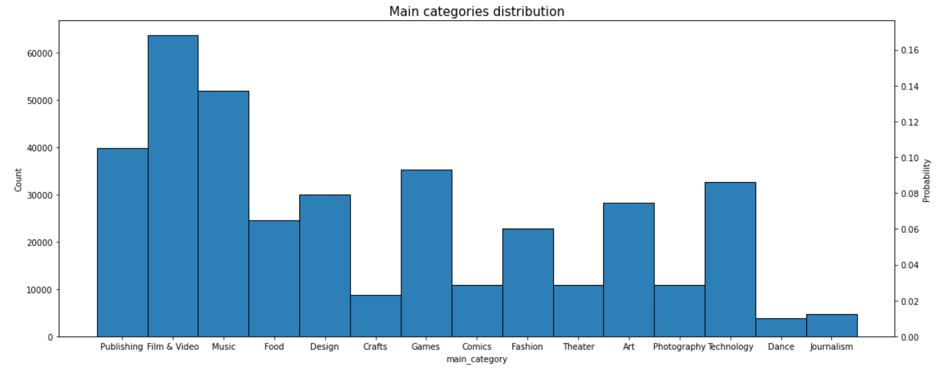
The number of categories in main_category and the distribution are appropriate. The expected number of dummy variables is 15. For category variable, have 159 unique values and is related to main_categories. Therefore, it can be left out in the first attempt.
Another categorical data is country:
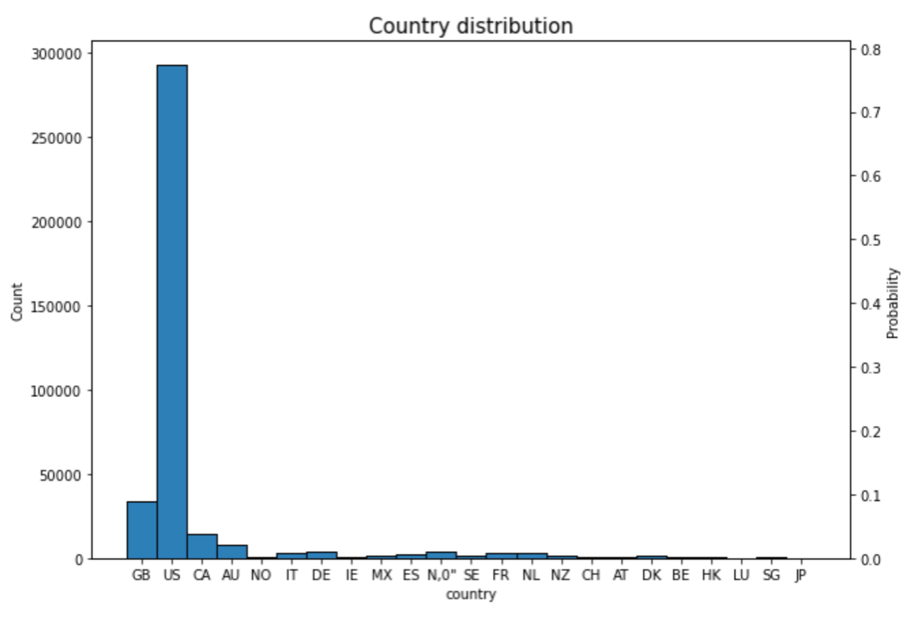
In this distribution, the ‘USA’ value contributes around 70 – 80 percent of the value, therefore binning can be used and a new variable is_USA will be made. For currency, since this variable is heavily followed country variable, it is unnecessary to include this in the feature set.
3/ Natural text data
Natural text data is data with phases, sentences paragraphs in natural language. This is mainly the focus of NLP, so the techniques are sorely derived from it. The main goal is to turn natural language text into a simple flat vector, with techniques to clean the vector entries and some methods to add a slight amount of semantic structure back into the vectors.
- Bag-of-words, Bag-of-n-grams is for extracting keywords in text that the model can derive useful information from.
- Parsing text, stemming and tokenization, chunking and part-of-speech tagging is a method to further processing the text features and including more semantic structure from the text back into the feature vector.
- Tf-Idf is a further developed technique to create features for a text that could be considered as a way to scale bag-of-words data.
In the example data, it is the ‘name’ variable:
Considering the setting of this example, the name of a project would need to have a keyword to attract potential backers. If it is a trend in words that need to be looked at, then simply identifying a trending keyword is enough. A popular way to visualize the frequency of words for text data is using a word cloud.

To compute features from the name variable, tf-idf will be used.
After feature engineering execution: Feature selection & model selection.
From the resulted feature set, feature selection either by statistic methods for filtering or wrapper and embedded method should be follow up to validate the feature engineering operation.
For the model, hyperparameter tuning & cross-validation will also need to be done.
As mentioned previously, 2 simple models SVM and Logistic Regression will be chosen so that at least 2 types of model can be considered in model selection.
The result for the first modeling process:
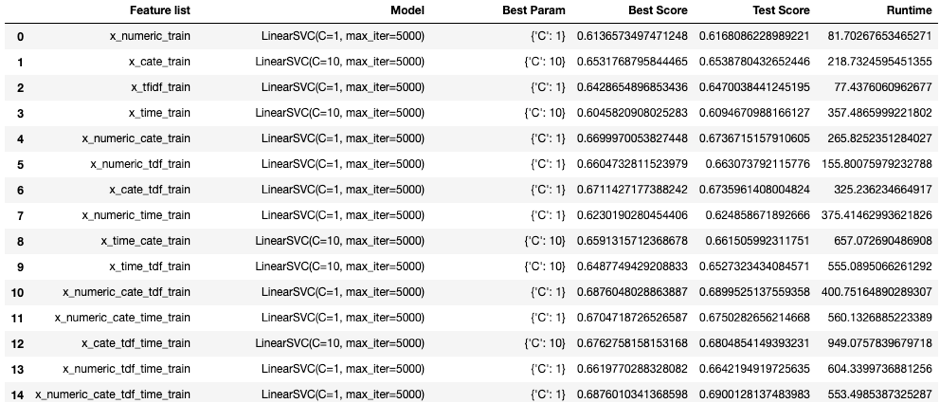
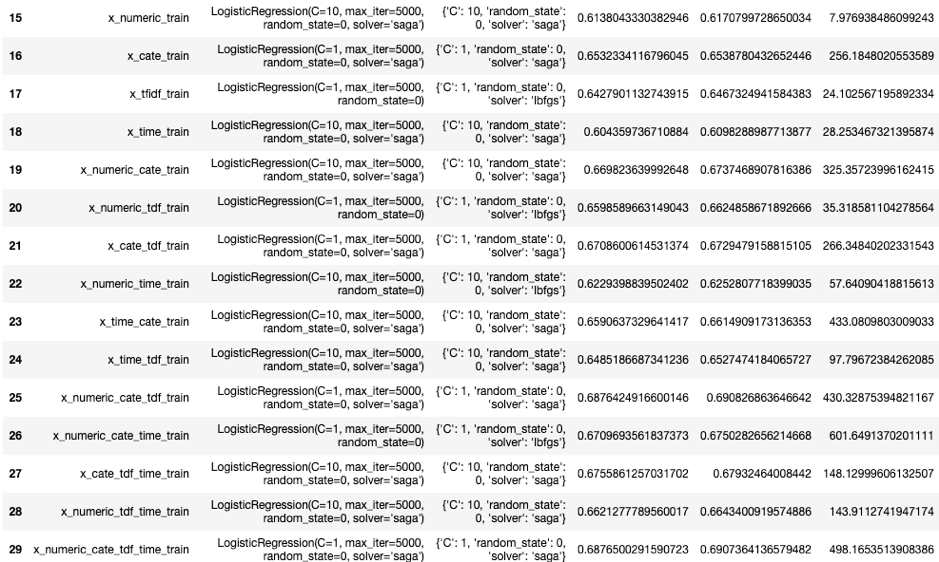
Performance of a model would need to consider both ‘Test Score’ and ‘Runtime’. The feature set of the highest score model with the appropriate candidate would be the promising one.
Expansion
- To create a new feature from 2 existed features apart from feature construction, interaction feature is also a possibility to introduce features’ relationship into the feature set but may be expensive in computing and training if doing it for a large number of features.
- For techniques of feature engineering to reduce dimensionality: PCA and model stacking with clustering. Note that the aim was not to reduce the number of dimensions as small as possible but to compress initial features set into the right number of features to be used for the model.
- For some other data, such as image and sound, it is hard to extract meaningful features since they only present as pixel or waveforms, which lack semantic meaning in that basic form.
- For sound, data can follow the form of sequence just like time-series data.
- For images, SIFT (Scale Invariant Feature Transform) and HOG (Histogram of Oriented Gradients) were the 2 standard image feature extractors. However, the deep learning approach has provided a way for automatic feature extraction that could be potential in replacing the manual steps in feature engineering.
- Feature learning, which can be said as automated feature engineering, is a possibility that has been applied widely, such as the automated feature extractor mentioned in the image data note above.
Conclusion
From the example, it is hope that based on data type a list of techniques and recommendations are helpful for an attempt to start a new modeling process.
The purpose of this blog post is to encouraging feature engineering practice apart from focusing on data and models. After research and tryout, intuition to create and manage features will potentially ease the difficulty when carrying out the modeling process.
Reference
Aishwarya, S. (2019). 6 Powerful Feature Engineering Techniques For Time Series Data (using Python). Analytics Vidhya. https://www.analyticsvidhya.com/blog/2019/12/6-powerful-feature-engineering-techniques-time-series/