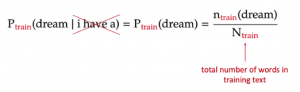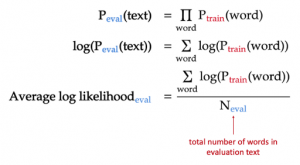The probability of each word is independent of any words before it.
Instead, it only depends on the fraction of time this word appears among all the words in the training text. In other words, training the model is nothing but calculating these fractions for all unigrams in the training text.
Estimated probability of the unigram ‘dream’ from the training text
Evaluating the model
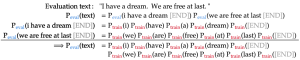
After estimating all unigram probabilities, we can apply these estimates to calculate the probability of each sentence in the evaluation text: each sentence probability is the product of word probabilities.
We can go further than this and estimate the probability of the entire evaluation text, such as dev1 or dev2. Under the naive assumption that each sentence in the text is independent of other sentences, we can decompose this probability as the product of the sentence probabilities, which in turn are nothing but products of word probabilities.
The role of ending symbols
As outlined above, our language model not only assigns probabilities to words but also probabilities to all sentences in a text. As a result, to ensure that the probabilities of all possible sentences sum to 1, we need to add the symbol [END] to the end of each sentence and estimate its probability as if it is a real word. This is a rather esoteric detail, and you can read more about its rationale here (page 4).
Evaluation metric: average log-likelihood
When we take the log on both sides of the above equation for the probability of the evaluation text, the log probability of the text (also called log-likelihood), becomes the sum of the log probabilities for each word. Lastly, we divide this log-likelihood by the number of words in the evaluation text to ensure that our metric does not depend on the number of words in the text.
For n-gram models, log of base 2 is often used due to its link to information theory (see here, page 21)
As a result, we end up with the metric of average log-likelihood, which is simply the average of the trained log probabilities of each word in our evaluation text. In other words, the better our language model is, the probability that it assigns to each word in the evaluation text will be higher on average.
Other common evaluation metrics for language models include cross-entropy and perplexity. However, they still refer to the same thing: cross-entropy is the negative of average log-likelihood, while perplexity is the exponential of cross-entropy.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.