Contents
Many data science teams have been chagrined to face seemingly mysterious occurrences of model failures with near-production data, despite taking all the prescribed methods to avoid overfitting. Recently, there has been a slew of papers published that attempt to get to the bottom of seeming ‘brittleness’ of various models.
One emerging idea is that many black-box ML models are ‘underspecified‘: a concept that given a set of data, there are many predictors that models could return with similar predictive risk. These risk-equivalent, near-optimal predictors do not encode identical ‘inductive biases’ that will generalize on different data sets. In other words, just because model A and model B have nearly identical performance, the pathways taken to conlude are not necessarily what we humans think they are. What is worse, if not explicitly encoded, such models may return predictors that rely on spurious features: present only in certain datasets but not others. Some have also pointed out that as models get bigger and more complex, there are more parameters than data points, thus solving problems using neural networks is de facto underspecified.
Explaining what the models do
Contrary to the assumption that most clients do not care about ‘how’ a model work, as long as it works well, there is an increasing call for data scientists to explain what the models do, and how do models arrive at a certain conclusion, especially the wrong ones. This is especially important in fields where what is at stake are human lives — such as medical imaging to aid clinical diagnosis.
Can all ML models be explained? Probably not equally easily for some models. A linear model is almost self-explanatory. But a neural network? An interesting field has emerged that attempts to explain the ‘activation’ regions that led the model to arrive at certain predictions, as illustrated by the picture below (Image from this paper).
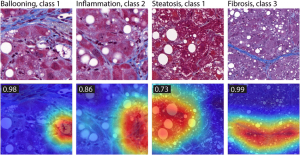
When you do see the right activation, then congratulations! Your model has probably encoded the right ‘inductive biases’ that you can then confidently explain to your clients.
The takeaway message from here is: there is no getting away from understanding what features are essential (vs. merely useful) in your model’s decision-making.
Please check our other blogs related to Machine Learning.
Machine Learning Blog
Hiring Data Scientist / Engineer
We are looking for Data Scientist and Engineer.
Please check our Career Page.
Data Science Project
Please also check about our Data Science Project example.
Vietnam AI / Data Science Lab

Please also visit Vietnam AI Lab